![]()
8. Boas Práticas de Visualização¶
A questão da Visualização de Dados vai muito além do processo de produzir gráficos com Python ou qualquer outra ferramenta. Você pode saber empregar a ferramenta corretamente e mesmo assim produzir visualizações erradas ou que não comunicam qualquer mensagem ao leitor. Por isso muitos livros de Visualização de Dados se quer apresentam qualquer linha de código. Eles focam no quê deve ser produzido para uma Visualização de Dados eficaz, em vez do como ou de como empregar corretamente as ferramentas. Princípios gerais para a preparação de figuras independem da ferramenta ou linguagem empregadas.
Buscamos apresentar alguns desses princípios ao longo do texto e vamos concluir aqui apenas com algumas boas práticas que você deve ter em mente ao produzir figuras com Python ou qualquer outra ferramenta. Existem muito boas referências atuais sobre o tema e sugiro você consultar, por exemplo, Kieran Healy (2019), Claus O. Wilke (2019) ou ainda Andy Kirk(2019) (veja a bibliografia no final do texto) e não teremos aqui a pretensão de esgotar o tema.
8.1. O Processo de Visualização de Dados¶
Uma visualização de algo muito simples e só para você pode talvez não exigir muito planejamento. Mas, para qualquer caso de maior interesse, a Visualização de Dados é um processo complexo e, portanto, uma tarefa que exige um certo planejamento e fases para que você possa alcançar um bom resultado.
Esse processo pode ser descrito de forma mais ou menos elaborada, mas acredito que um bom ponto de partida é pensarmos ao menos em quatro passos para a elaboração de Visualizações corretas e eficazes dos dados. Dessas, apenas a última envolve efetivamente programação ou o uso de ferramentas.
import matplotlib
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(10,2.5))
for i, fase in enumerate(['O que?','Para Quem?','Desenhe','Execute']):
ax = fig.add_subplot(1,4,i+1)
ax.set(facecolor = '#FFD700')
plt.xlim([0, 400])
plt.ylim([0, 400])
plt.text(200,200,fase, horizontalalignment='center', verticalalignment='center',
fontsize=24, c='w', family='fantasy', weight='bold')
plt.xticks([])
plt.yticks([])
plt.tight_layout()
plt.show()

8.1.1. O quê?¶
Se você preferir pode chamar essa fase de Formulação do Problema, mas acho mais simples dizermos simplesmente O quê? Essa é uma pergunta essencial. Afinal, o quê estamos buscando apresentar ou visualizar nos dados? Já discutimos que existem gráficos de Exploração e de Apresentação de resultados e, antes de produzir figuras você deve ter em mente que tipo de gráfico você quer produzir.
Aqui você também deve levar em conta quais dados serão empregados para produzir a visualização. Como você pôde ver ao longo deste texto muitas das visualizações produzidas requerem seleções e tratamento dos dados para que as visualizações possam ser produzidas e o entendimento dos dados é aqui essencial.
Responder à pergunta o quê? vai ajudá-lo a selecionar os dados e a decidir até que tipo de gráficos empregar.
8.1.2. Para quem?¶
Os gráficos devem transmitir os dados com precisão e, mesmo que sejam gráficos só para você, eles devem ter um aspecto agradável e que facilite você alcançar a mensagem. Afinal, você poderá ter de rever esse gráfico muito tempo depois de produzi-lo e uma boa apresentação ajudará você a voltar mais facilmente à mensagem que foi produzida.
Mas, em geral, queremos compartilhar nossos resultados, e para quem? iremos produzir uma visualização passa a ser uma pergunta essencial que vai direcionar o que devemos fazer para produzir uma visualização eficaz.
Gráficos Exploratórios são muitas vezes compartilhados com colegas que estão trabalhando no mesmo conjunto de dados, podem ser dados de uma pesquisa acadêmica ou a análise de dados de vendas ou de produção de uma empresa. Esses gráficos podem ser menos elaborados que gráficos produzidos para Apresentação de Resultados uma vez que todos compartilham o contexto e uma série de informações que não precisarão ser representadas. Isso não descarta um cuidado mínimo com a apresentação das figuras. Como antes, os gráficos podem ter de ser revistos muito depois de criados e a falta de cuidados na apresentação pode levar a transmissão de mensagens erradas sobre os dados ou, no mínimo, levar ao desinteresse às mensagens apresentadas. Também é importante lembrar que os gráficos exploratórios precisam ser refeitos e alterados várias vezes na busca de informações sobre os dados.
Já gráficos de Apresentação precisam ser, além de claros, atraentes e convincentes para o público que direcionamos a apresentação. Uma boa ou má apresentação pode ser a diferença para ter um projeto aprovado na empresa, um artigo científico aceito para publicação ou uma proposta de negócio aceita ou não. Nesses casos é importante você ter claro o público a que se destina a apresentação do gráfico. Públicos diferentes terão conhecimentos diferentes sobre o contexto dos dados, e podem ter uma linguagem e expectativas muito diferentes. Você pode pensar sobre gráficos comunicam dados sobre uma pandemia para o público geral e leigo, e os que são produzidos para a comunidade científica em um artigo.
8.1.3. Desenhe¶
Um gráfico pode ser construído apenas com lápis e papel e, mesmo assim, comunicar corretamente os dados. Você não precisa necessariamente desenhar o gráfico no papel mas, independente da linguagem ou da ferramenta que você irá empregar para produzir a sua visualização você precisa, antes de mais nada mentalizar essa figura, você precisa ter em mente que figura deseja produzir.
Boa parte deste texto se dedicou exatamente a ajudá-lo a identificar que gráficos podem ser construídos para cada tipo de pergunta que queremos responder sobre os dados (Evolução, Distribuição, Quantidades e Proporções, ou Relações). Você pode assim, mentalizar o tipo de visualização que deseja construir, ou pode mesmo desenhar e por suas ideias no papel antes de realiza-las. Isso será ainda mais importante se não for você que vai produzir as visualizações, mas um programador ou alguém com algum conhecimento de uma ferramenta.
8.1.4. Execute¶
Por último, já está tudo definido e o que você tem a fazer é empregar o Python, ou uma outra ferramenta, o melhor possível para produzir a sua visualização. Esse é um processo que requer um certo domínio das ferramentas empregadas e envolve muitas vezes várias experimentações e execuções para se chegar ao resultado desejado.
É claro que essas fases diferem caso a caso e podem ser todas feitas em conjunto para casos simples, mas há também questões mais sofisticadas como, por exemplo, quando se tratam de criar pipelines de visualização de dados (quando dados alimentam visualizaçõesque serão atualizadas continuamente, ou de tempos em tempos, fazendo parte de uma linha de produção). Algo que é muito comum em dashboards, produção de relatórios periódicos de empresas etc. mas também não tão incomum em pesquisas científicas que envolvem milhares de dados produzidos continuamente (dados astronômicos, de clima etc.)
A seguir você verá alguns exemplos de gráficos que ajudam a entender a diferença de gráficos de apresentação para diferentes públicos.
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
data = sns.load_dataset('titanic')
data = pd.DataFrame(data.groupby('class')['who'].count()).reset_index()
data.columns = ['class','qty']
display(data.head())
| class | qty | |
|---|---|---|
| 0 | First | 216 |
| 1 | Second | 184 |
| 2 | Third | 491 |
# Adaptado de Nic Fox, How to Make Better Looking Charts in Python
plt.figure(figsize=(12,4))
plt.subplot(1,2,1)
plt.bar(x='class', height='qty', data=data)
plt.subplot(1,2,2)
sns.barplot(data=data, x='class', y='qty', palette=['#eb3434', '#eb7a34', '#ebae34'])
plt.xlabel('')
plt.ylabel('')
plt.title('Titanic, Passageiros por Classe', size=16, color='#4f4e4e', weight='bold')
plt.xticks(size=14, color='#4f4e4e')
# plt.yticks([], [])
plt.text(x=1, y=520, s='Maior parte dos passageiros em 3a Classe',
color='#4f4e4e', fontsize=12, horizontalalignment='center')
plt.text(x=0, y=10, s="10",
color='white', fontsize=16, horizontalalignment='center')
plt.text(x=1, y=10, s="25",
color='white', fontsize=16, horizontalalignment='center')
plt.text(x=2, y=10, s="50",
color='white', fontsize=16, horizontalalignment='center')
plt.ylim([0,550])
sns.despine(left=True)
plt.tight_layout()
plt.show()
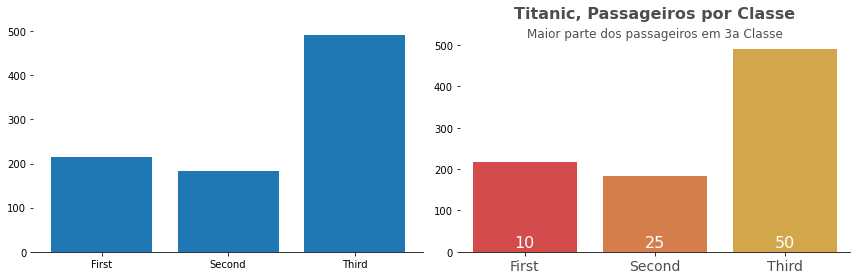
O primeiro gráfico pode ser um gráfico de trabalho, ou de Exploração. Ele pode eventualmente apresentar menos ornamentos e detalhes e, mesmo assim, ser eficiente em transmitir os dados para pessoas que compartilham o contexto dos dados. Mas para a Apresentação, um gráfico como ao lado, deve comunicar melhor os dados.
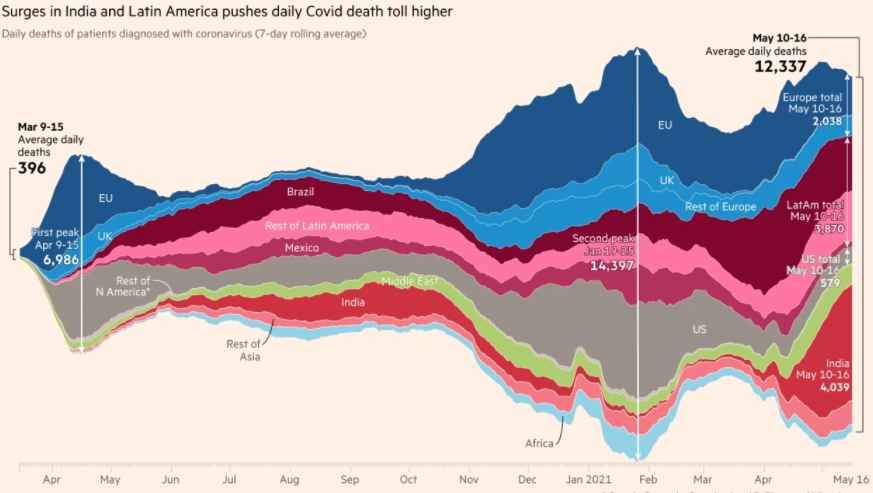
Este gráfico de Evolução dos Casos de Covid até Maio de 2020 é um gráfico de Apresentação e, certamente, muitas visualizações foram produzidas antes de se chegar ao resultado final. O gráfico tem também um público alvo específico que orienta como são apresentadas as informações. (source: Financial Times, Coronavirus tracker: the latest figures as countries fight the Covid-19 resurgence | Free to read)
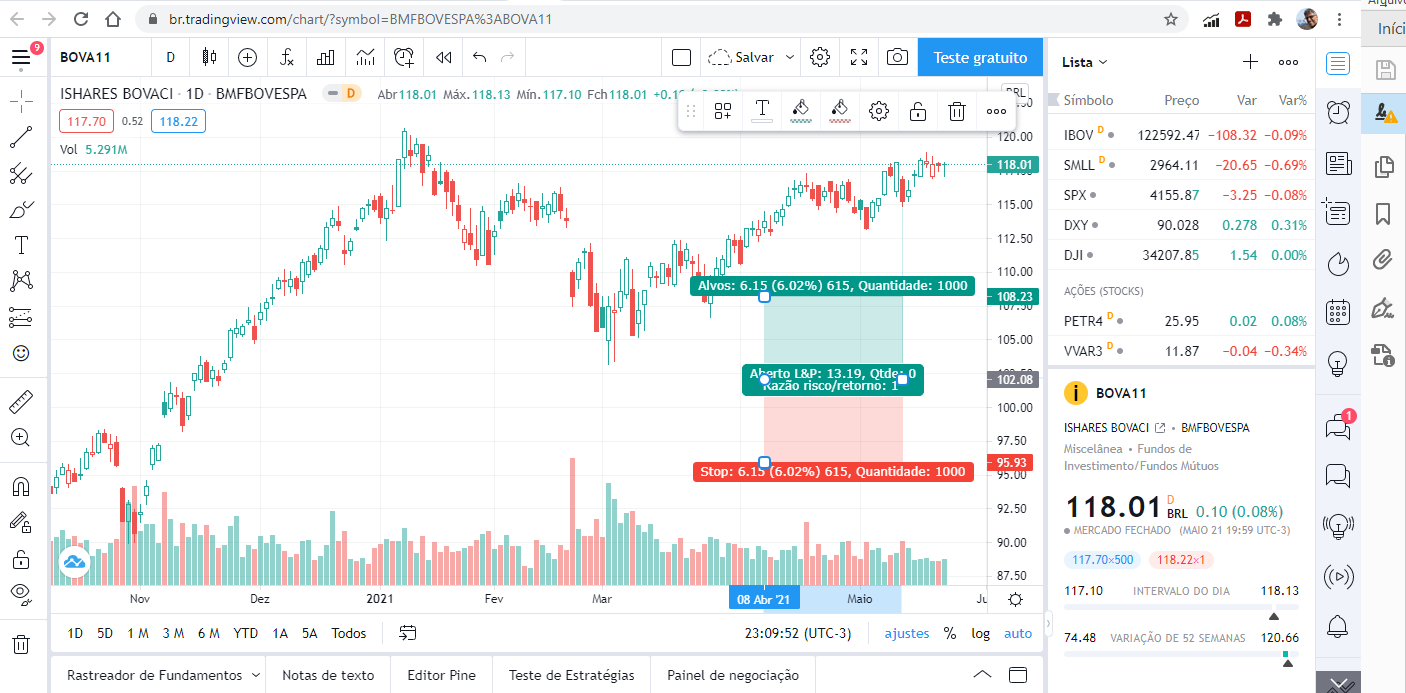
Mais um exemplo de gráfico eficiente. Um gráfico que combina uma série de elementos como gráficos de caixa diários e linhas de tendência faz parte das ferramentas de um público bastante técnico de traders operam na bolsa de valores.
8.2. Design das Figuras¶
\(\bigstar \text{ }\) Most people make the mistake of thinking design is what it looks like… People think it’s this veneer — that the designers are handed this box and told, ‘Make it look good!’ That’s not what we think design is. It’s not just what it looks like and feels like. Design is how it works. (Steve Jobs, The New York Times Magazine, https://www.nytimes.com/2003/11/30/magazine/the-guts-of-a-new-machine.html).
Talvez não seja exatamente essa a interpretação, mas eu acredito que sim. O bom design é simplesmente aquilo que funciona e, no caso das Visualização de Dados funcionar significa comunicar os dados.
A visualização, antes de tudo, precisa transmitir os dados com precisão e, nem por isso, deve deixar de ter um aspecto agradável. Um bom aspecto das figuras permite o leitor chegar mais facilmente à mensagem e, portanto, torna a visualização mais eficaz.
O gráfico de Evolução de Casos de Covid que exibimos acima é um gráfico para um público em geral, mas mesmo assim para leitores do Financial Times e, certamente, pessoas habituadas a ler e interpretar gráficos e, para eles, esse gráfico aparentemente funciona e, portanto, tem um bom design. O poster de um trabalho científico ou uma tese de doutorado empregarão designs diferentes e é comum a comunidade acadêmica não ver com bons olhos cores e muitos ornamentos nas figuras. Mas isso é algo que, felizmente, vem mudando com alguns trabalhos mais recentes privilegiando não só a pesquisa mas também a comunicação, buscando assim compartilhar do conhecimento, o que parece ser uma tendência.
Mas, se por um lado é difícil definir um bom design, vemos claramente alguns aspectos que levam a designs ruins.
8.2.1. Figuras Feias¶
Ao produzir uma figura você sempre estará limitado ao melhor que pode fazer. Os recursos que conhece, as exigências de tempo que tem para produzir a figura etc. Mas não limites nas coisas erradas que podemos fazer.
Algumas figuras são simplesmente feias, esteticamente ruins, de mal gosto. Isso pode ter vários motivos mas em geral erramos pelo excesso. Combinações em excesso de cores, excesso de elementos decorativos, múltiplos tamanhos e tipos de fontes na mesma figura, muitos estilos de linha mal empregados, figuras poluídas etc. enfim são incontáveis os erros que podemos cometer. Embora uma figura ser feia possa ser um pouco subjetivo devemos ter em mente que as figuras para serem eficazes precisam ser econômicas. Os recursos que empregamos devem ter o objetivo de comunicar os dados e não simplesmente enfeitar a figura. Esse princípio nem sempre produzirá as melhores figuras, mas parece evitar os principais problemas e, em geral, pode ser aplicado à maior parte dos casos. Devemos buscar produzir figuras, sempre que possível, com um pequeno número de cores, estilos de linha e fontes de texto. A maior parte dos pacotes e ferramentas, assim como o Matplotlib já produz ornamentos padrão que, na ausência de melhores escolhas, trazem algum resultado.
Figuras de mal gosto, com má qualidade e pouco atraentes prejudicam a comunicação da mensagem, o que pode ocorrer pelo simples fato do leitor se indispor diante de uma figura pouco atrativa e convincente, podendo a mensagem ser ignorada, mal interpretada ou até mesmo rejeitada pelo leitor.
import numpy as np
plt.figure(figsize=(12,4))
plt.subplot(1,2,1)
x = np.arange(-5, 5, 0.01)
y = 1 / (1 + np.exp(-x))
plt.plot(x,y,'b:',label='Sigmoid')
plt.fill_between(x,y,color='#00FF00')
y = np.tanh(x)
plt.plot(x,y,'r-',label='Tanh')
plt.fill_between(x,y,color='salmon')
plt.hlines(0,-5,5,'k')
plt.vlines(0,-1,1,'k')
plt.title(' Funções\nde Ativação', fontsize=24, color='violet', y=0.85, loc='left', weight='bold', style='italic')
plt.xlabel('Input', family='monospace', fontsize=14, color='#FF00FF', style='italic')
plt.ylabel('Output', family='sans-serif', fontsize=16, color='green')
plt.xticks(rotation=60, fontsize=20, color='green')
plt.yticks(rotation=60, color='#FF00FF')
plt.legend(title='Activation', loc='lower left',fontsize=14)
plt.grid()
plt.subplot(1,2,2)
x = np.arange(-5, 5, 0.01)
y = 1 / (1 + np.exp(-x))
plt.plot(x,y,label='Sigmoid',c='blue')
y = np.tanh(x)
plt.plot(x,y,label='Tanh',c='r')
plt.hlines(0,-5,5,'k',linestyles=':',lw=1)
plt.vlines(0,-1,1,'k',linestyles=':',lw=1)
plt.title('Funções de Ativação', fontsize=14, weight='bold')
plt.xlabel(r"$x$", fontsize=12)
plt.ylabel(r"$f(x)$", fontsize=12)
plt.legend(title='Activation', loc='best')
plt.text(0.5, 0.1, r"$\frac{e^{x} - e^{-x}}{e^{x} + e^{-x}}$", fontsize=16, color='r')
plt.text(-4, -0.25, r"$\frac{1}{1 + e^{-x}}$", fontsize=16, color='b')
plt.tight_layout()
plt.show()
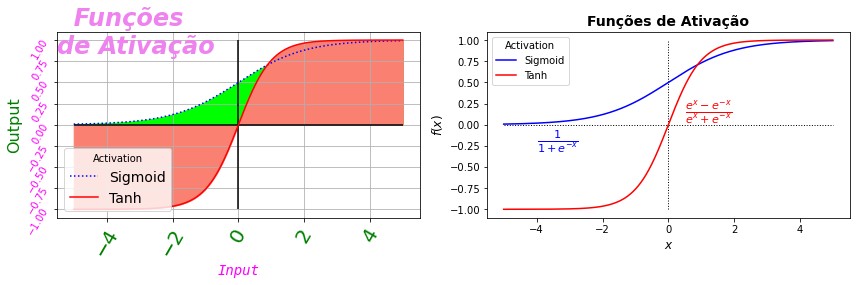
Excesso de cores, estilos de linha, fontes etc. prejudicam a comunicação, o que pode ocorrer pela simples indisposição do leitor para uma figura pouco atraente, fazendo com que a mensagem seja ignorada, mal interpretada ou mesmo rejeitada. O uso econômico de recursos, não é uma regra, mas em geral previne grande parte dos problemas neste caso e produz figuras mais elegantes e comunicativas.
8.2.2. Exibir Dados Errados¶
Uma visualização de dados, antes de mais nada, deve comunicar os dados de forma correta e com precisão. Ela não pode enganar ou distorcer os dados para o leitor. Se dois valores são diferentes e parecem iguais na visualização a visualização está errada. Se os valores são iguais e parecem diferentes, do mesmo modo a visualização está errada. Este é um grande problema de design e muitas vezes produzimos visualizações para apresentar o que queremos ver nos dados e não aquilo que os dados mostram. Se perguntar se você está exibindo a informação correta pode ser suficiente para você perceber um erro como esse e corrigir a figura. Infelizmente isso nem sempre é fruto apenas de erro ou descuido de quem produz uma visualização sendo muitas vezes um meio empregado para passar uma mensagem enganosa para o leitor.
Os gráficos abaixo mostram erros de design bastante comuns que cometemos ao tratarmos a escala dos valores para visualização.
data = sns.load_dataset('mpg')
display(data.head())
| mpg | cylinders | displacement | horsepower | weight | acceleration | model_year | origin | name | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 18.0 | 8 | 307.0 | 130.0 | 3504 | 12.0 | 70 | usa | chevrolet chevelle malibu |
| 1 | 15.0 | 8 | 350.0 | 165.0 | 3693 | 11.5 | 70 | usa | buick skylark 320 |
| 2 | 18.0 | 8 | 318.0 | 150.0 | 3436 | 11.0 | 70 | usa | plymouth satellite |
| 3 | 16.0 | 8 | 304.0 | 150.0 | 3433 | 12.0 | 70 | usa | amc rebel sst |
| 4 | 17.0 | 8 | 302.0 | 140.0 | 3449 | 10.5 | 70 | usa | ford torino |
plt.figure(figsize=(12,4))
plt.subplot(1,2,1)
sns.barplot(x='model_year',y='mpg',data=data, color='red', alpha=0.8, errwidth=1)
plt.title('MPG por ano dos Modelos', fontsize=14, weight='bold')
plt.ylim([15,35])
plt.yticks([])
plt.subplot(1,2,2)
sns.barplot(x='model_year',y='mpg',data=data, color='lightgreen', alpha=0.7, errwidth=1)
plt.title('MPG por ano dos Modelos', fontsize=14, weight='bold')
plt.yticks([])
plt.tight_layout()
plt.show()
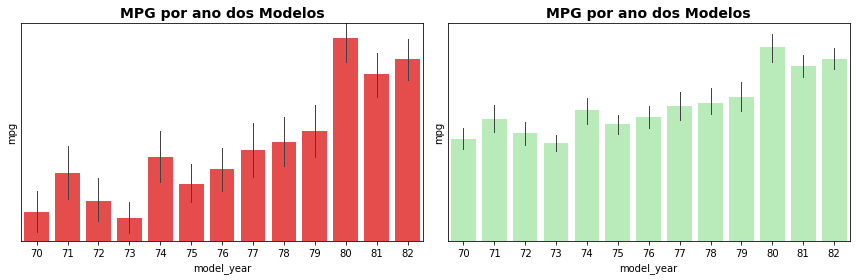
Aqui o segundo gráfico comunica de forma muito mais honesta os dados. No primeiro, os dados da escala mpg iniciam no valor 15 e fazem com que tenhamos a impressão de que os valores crescem ano a ano muito mais do que crescem realmente.
fig = plt.figure(figsize=(12,4))
ax1 = plt.subplot2grid((3,3), (0,0), rowspan=3)
ax2 = plt.subplot2grid((3,3), (0,1), rowspan=3, colspan=2)
sns.lineplot(x='model_year',y='mpg',data=data, color='red', alpha=0.8, ax=ax1)
ax1.set_title('MPG por ano dos Modelos', fontsize=14, weight='bold')
ax1.set_yticks([])
sns.lineplot(x='model_year',y='mpg',data=data, color='lightgreen', ax=ax2)
ax2.set_title('MPG por ano dos Modelos', fontsize=14, weight='bold')
ax2.set_yticks([])
plt.tight_layout()
plt.show()
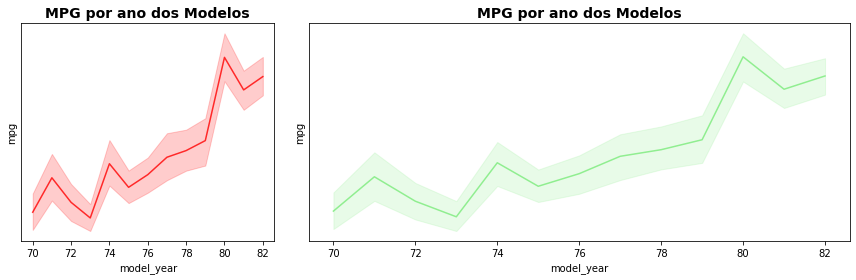
O mesmo tipo de erro pode produzido com a escolha de tamanho dos eixos e escalas das figuras. No primeiro gráfico o crescimento de mpg ao longo dos anos é intensificado ao empregarmos um eixo mais estreito para representarmos os anos dos modelos.
8.2.3. Overplotting e Chartjunk¶
Excesso de dados em um gráfico e lixo gráfico são dois problemas comuns com efeitos bastante semelhantes mas não são necessariamente o mesmo problema. Um gráfico de caixa com muitos outliers pode ser bastante ilegível e, caso não tenham significado útil, constituem um lixo gráfico que pode então ser omitido. Do mesmo modo um gráfico de pontos que aprensente um número excessivo de pontos pode ser ajustado para reduzir granularidade e exibir um menor número de pontos no gráfico.
Alguns elementos visuais são úteis para evitar ou ao menos minimizar esses problemas. O emprego de cores mais saturadas (básicas e fortes) tende a reforçar a aparência de overplotting e o chartjunk e você pode então empregar cores mais suaves ou ainda a transparência de cores (parâmetro alpha= do Matplotlib que empregamos com frequência ao longo de todo o texto). Outro recurso é eliminar pontos ou linhas limite desnecessárias ou discrepantes, ou minimizar a aparência deles.
data = sns.load_dataset('fmri')
data = data[ data.subject.isin(['s1','s2','s3','s4','s5']) ]
display(data.head())
| subject | timepoint | event | region | signal | |
|---|---|---|---|---|---|
| 1 | s5 | 14 | stim | parietal | -0.080883 |
| 9 | s5 | 18 | stim | parietal | -0.040557 |
| 10 | s4 | 18 | stim | parietal | -0.048812 |
| 11 | s3 | 18 | stim | parietal | -0.047148 |
| 12 | s2 | 18 | stim | parietal | -0.086623 |
plt.figure(figsize=(12,4))
plt.subplot(1,2,1)
for sub in data.subject.unique():
plt.plot(data[ data.subject == sub ].timepoint, data[ data.subject == sub ].signal , label=sub, alpha=0.8)
plt.title('fMRI signals by subject', fontsize=14, weight='bold')
plt.xlabel('timepoint')
plt.legend(title='subject')
plt.subplot(1,2,2)
sns.lineplot(x='timepoint', y='signal', data=data, hue='subject' )
plt.title('fMRI signals by subject', fontsize=14, weight='bold')
plt.tight_layout()
plt.show()
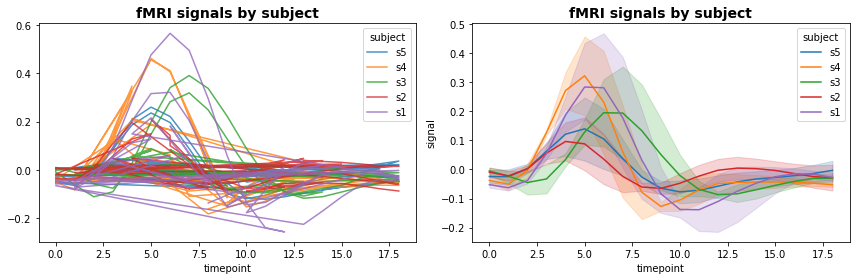
Aqui empregamos o lineplot do Seaborn para miminar as linhas de vários signais do primeiro gráfico tornando a figura bastante mais clara e elegante. Algo semelhante pode ser feito com gráficos de dispersão com excesso de pontos ou mesmo em gráficos de caixa.
data = sns.load_dataset('diamonds')
display(data.head())
| carat | cut | color | clarity | depth | table | price | x | y | z | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.23 | Ideal | E | SI2 | 61.5 | 55.0 | 326 | 3.95 | 3.98 | 2.43 |
| 1 | 0.21 | Premium | E | SI1 | 59.8 | 61.0 | 326 | 3.89 | 3.84 | 2.31 |
| 2 | 0.23 | Good | E | VS1 | 56.9 | 65.0 | 327 | 4.05 | 4.07 | 2.31 |
| 3 | 0.29 | Premium | I | VS2 | 62.4 | 58.0 | 334 | 4.20 | 4.23 | 2.63 |
| 4 | 0.31 | Good | J | SI2 | 63.3 | 58.0 | 335 | 4.34 | 4.35 | 2.75 |
plt.figure(figsize=(12,4))
plt.subplot(1,2,1)
for i, c in enumerate(data.cut.unique()):
plt.boxplot(data[ data.cut == c ].z, positions=[i])
plt.title('Diamonds z measure', fontsize=14, weight='bold')
plt.ylabel('z')
plt.xticks(ticks=[0,1,2,3,4],labels=data.cut.unique())
plt.subplot(1,2,2)
for i, c in enumerate(data.cut.unique()):
plt.boxplot(data[ data.cut == c ].z, positions=[i],widths=0.4,flierprops=dict(markerfacecolor='r', alpha=0.2))
plt.title('Diamonds z measure', fontsize=14, weight='bold')
plt.ylim([0.2,9])
plt.ylabel('z')
plt.xticks(ticks=[0,1,2,3,4],labels=data.cut.unique())
plt.tight_layout()
plt.show()
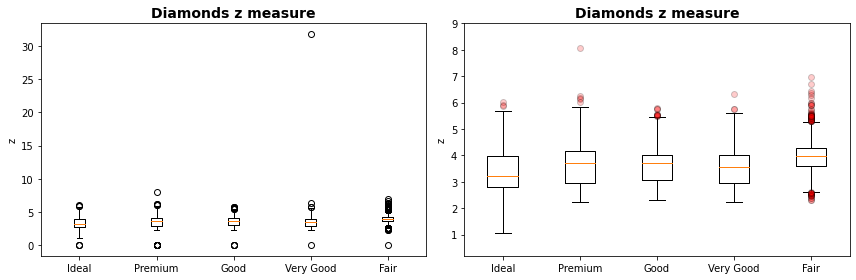
Um único valor (em very good) comprometer completamente a visualização no primeiro gráfico. Excluído da figura e adicionando transparência às cores dos outliers você pode ver com mais clareza a dispersão de medida de para cada tipo de diamante e seus valores discrepantes.
8.2.4. Mensagem Correta¶
Cores, destaques no gráfico e outros recursos podem e precisam ser empregados para comunicar a sua mensagem corretamente. Destacar ou colorir dados irrelevantes podem não só poluir a figura como provocar uma interpretação errada ou desatenciosa da mensagem. Saber empregar as cores de forma eficiente pode ser uma arte, mas é necessário praticá-la para se produzir boas figuras e boas visualizações dos dados.
Abaixo empregamos os dados coletados por Florence Nightingale (vimos os gráficos Nightingale Rose no capítulo de Quantidades e Proporções) sobre os feridos na Gerra da Crimeia para ilustrar o erro de design que podemos causar ao ignorar o uso dos recursos visuais para comunicar a mensagem que queremos.
data= pd.read_csv('https://raw.githubusercontent.com/Rogerio-mack/Visualizacao-de-Dados-em-Python/main/data/nightingale.csv',index_col=0)
data = data[ data.Year == 1855 ]
data.head()
| Month | Year | Army | Disease | Wounds | Other | Disease.rate | Wounds.rate | Other.rate | |
|---|---|---|---|---|---|---|---|---|---|
| Date | |||||||||
| 1855-01-01 | Jan | 1855 | 32393 | 2761 | 83 | 324 | 1022.8 | 30.7 | 120.0 |
| 1855-02-01 | Feb | 1855 | 30919 | 2120 | 42 | 361 | 822.8 | 16.3 | 140.1 |
| 1855-03-01 | Mar | 1855 | 30107 | 1205 | 32 | 172 | 480.3 | 12.8 | 68.6 |
| 1855-04-01 | Apr | 1855 | 32252 | 477 | 48 | 57 | 177.5 | 17.9 | 21.2 |
| 1855-05-01 | May | 1855 | 35473 | 508 | 49 | 37 | 171.8 | 16.6 | 12.5 |
plt.figure(figsize=(12,4))
plt.subplot(1,2,1)
plt.plot(data['Month'],data['Disease.rate'], alpha=1.0, color='lightblue', label='Disease')
plt.fill_between(data['Month'],data['Disease.rate'], alpha=0.8, color='lightblue')
plt.plot(data['Month'],data['Wounds.rate'], alpha=1.0, color='red', label='Wounds')
plt.fill_between(data['Month'],data['Wounds.rate'], alpha=0.9, color='red')
plt.plot(data['Month'],data['Other.rate'], alpha=1.0, color='grey', label='Others')
plt.fill_between(data['Month'],data['Other.rate'], alpha=0.4, color='grey')
plt.title('Injuries Crimeia War (1855)', fontsize=14, weight='bold')
plt.legend()
plt.subplot(1,2,2)
plt.plot(data['Month'],data['Disease.rate'], alpha=1.0, color='r', label='Disease')
plt.fill_between(data['Month'],data['Disease.rate'], alpha=0.9, color='r')
plt.plot(data['Month'],data['Wounds.rate'], alpha=1.0, color='lightblue', label='Wounds')
plt.fill_between(data['Month'],data['Wounds.rate'], alpha=0.9, color='lightblue')
plt.plot(data['Month'],data['Other.rate'], alpha=1.0, color='grey', label='Others')
plt.fill_between(data['Month'],data['Other.rate'], alpha=0.4, color='grey')
plt.title('Injuries Crimeia War (1855)', fontsize=14, weight='bold')
plt.legend()
plt.tight_layout()
plt.show()
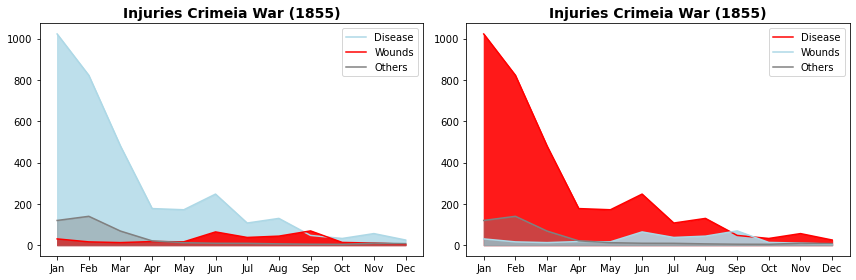
Qual gráfico você acredita que Florence Nightingale empregaria para comunicar sua mensagem? No primeiro gráfico a cor vermelha leva facimente o leitor a interpretar os casos de Wounds (feridos no combate) como o caso crítico, entretanto, o que problema que ela queria ressaltar era de que o número de soldados comprometidos por doenças superava em muito os soldados feridos no confronto. Ela, certamente, iria preferir o segundo gráfico para passar sua mensagem.
Existe certamente muitos outros pontos e discussões de como produzir figuras mais corretas e atraentes. Mas temos aqui nosso espaço limitado e espero ter apresentado exemplos suficientes para que você entenda a relevância disso na hora de construir visualizações dos dados e dispertado seu interesse para explorar outras referências como as que citamos no início deste capítulo.
8.3. Escolhendo a Ferramenta Certa¶
Nos limitamos a empregar aqui o Python e as bibliotecas Matplotlib e Seaborn. Mas mesmos para essas ferramentas não cobrimos todos os seus recursos havendo ainda recursos importantes como gráficos de imagens, animações, gráficos iterativos, mapas etc. e ainda outros pacotes que interagem com o Python e o Matplotlib, como o Plotly e o Broken, e espero poder disponibilizar materiais adicionais sobre isso ao longo do tempo no site do livro. De qualquer modo, ao falarmos de boas práticas para a produção de visualizações, vamos finalizar apresentando brevemente alguns aspectos sobre a escolha de ferramentas de visualização.
\(\bigstar \text{ }\) O primeiro princípio que você deve ter em mente é que o melhor software de visualização, seja uma ferramenta ou uma linguagem, é aquele que permite a você fazer os gráficos de você precisa (adaptação livre de Wilke (2019)).
Nenhum software ou linguagem será útil para você se você não consegue obter dele os gráficos de que precisa. E isso pode ser simplesmente pelo fato de você não conhecer a ferramenta ou a linguagem. Mas, na medida que as ferramentas de que você dispõe passam a ser insufientes para a sua necessidade, você irá precisar gastar algum tempo para entendê-las e saber empregá-las.
De qualquer modo o grande divisor nessa escolha de ferramentas parece ser entre o uso de ferramentas interativas de produção de gráficos e o uso de uma linguagem de programação.
Existem muito boas ferramentas interativas de exploração e análise de dados comerciais que oferecem grandes facilidades de visualização como o Tableau, PowerBI, Qlik e Google Data Studio, havendo ainda ferramentas para edição mais elaboradas de gráficos de apresentação como o Inkscape, TikZ etc. a principal limitação dessas ferramentas, e o principal motivo pelo qual damos preferência ao uso de linguagens de programação, é capacidade de reprodutibilidade dos resultados e a flexibilidade. Ferramentas (mas não linguagens de programação) estão limitadas em geral a um conjunto de funções pré definidas disponíveis, e resultados diferentes dos fornecidos por essas funções são bastante difíceis de serem obtidos com as ferramentas. Além disso, em geral, a reprodutibilidade de um gráfico interativo pode envolver ações manuais que podem não ser facilmente reproduzidas.
As linguagens, por outro, são altamente flexíveis e o código pode ser sempre replicado e reutilizado para reprodutibilidade. O Python, entretanto, não é a única linguagem disponível para visualização. O R, por exemplo, é uma linguagem e um ambiente para computação estatística e gráficos, e também muito empregada para análise e visualização de dados. O pacote ggplot2 do R é certamente hoje o pacote de visualização científica mais profissional para a visualização de dados (supera mesmo o Matplotlib e o Seaborn) e tem como diferencial implementar uma interface que separa o conteúdo (dados) e o design da figura, tornando a criação de gráficos bastante mais flexível. A linguagem D3.js é baseada no JavaScript e oferece uma maneira fácil de criar e controlar formulários gráficos interativos para execução em navegadores da web. Por último, mais recentemente, a linguagem Julia compartilha muitas das características do Python e vem crescendo como uma alternativa para visualização científica de dados.